| Top of GSFF | Index | Table of Contents | Feedback |
Extract Creation Processes
Introduction
A range of Callista jobs create data extracts as their output. In Callista there are three major approaches to the production of extracts.
Number One
A number of extract files are created in the Statistics Subsystem as part of the Government reporting process. These files are produced from data stored in Callista and are formatted in accordance with the file format specifications provided by DIISRTE. They are written to a secure directory, from which the files can be copied and used in the Government statistical package and for analysis by the institution using an ad-hoc query tool. The Tertiary Admissions Centre statistics process uses a similar approach.
Number Two
The second approach to data extract creation involves those jobs which extract Callista data into specially created Extract Tables. By writing programs which access views of the Extract Tables, individual institutions are able to customise the content and appearance of files, correspondence, reports or displays of information produced from the extracted data.
The second approach, extraction of data into Extract Tables, is the subject of this section. This methodology will eventually be retro-fitted, where appropriate, to extracts which currently use the third approach, as it simplifies the building of 'end use' programs by individual institutions.
Number Three
The third approach is used by some processes in earlier (prior to release 2.0) releases. In these cases, extract files of pipe delimited text are created. These files can be accessed by custom programs created by individual institutions.
Other processes within Callista extract data for immediate use within the process. The production of Admission Offer Letters takes this approach, extracting Admission Application Course and Unit data for immediate inclusion in a letter. In these cases the extracted data is not 'stored'.
Extraction of Data Into Extract Tables
Methodology
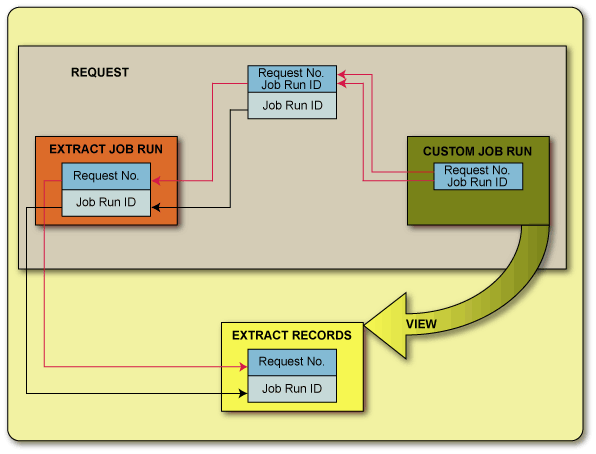
Jobs which produce output to Extract Tables are run through Job Scheduler in the usual way. Usually the job will have the Pass Request Job Run ID check box set (JBSF4110). This indicates that the unique reference code which identifies the particular run request/job run instance is passed as a parameter to the job (and is stored with the output).
This strategy enables institutions to custom build programs (refer to technical documentation) which access data in the Extract Tables and use this data to produce files, correspondence, reports or displays of information, in the format of their choosing. A custom program is linked to its extract job by recording a dependency in JBSF4140. When the custom program and the extract job are run in the same job request, the custom program uses its Job Run ID to determine the Request Number of the request in which it is being run. It then locates the Job Run ID of the most recent extract job run in that request. Extract records with the appropriate Job Run ID are then presented by the view.
Extract Jobs
Only specific jobs produce output to Extract Tables. Testamur Extract and Enrolment Form Extract are two examples.
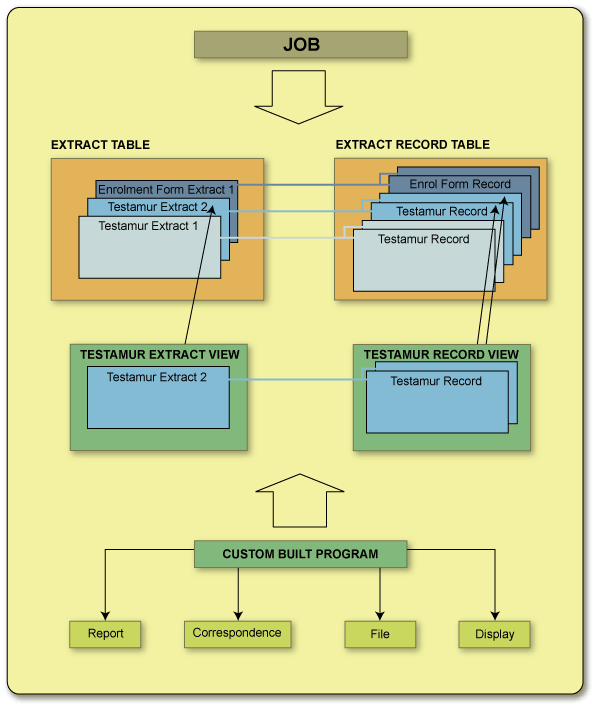
Data Extract Tables
This method uses a set of generic tables to hold output from any extract producing job. For each Extract Type, specific views have been created to present only data belonging to that Extract Type. It is these views which are targeted by the custom built programs.
Extract Views
The views which have been created to present data stored in the Extract Tables are designed to make the data more accessible. Each view is specific to a particular Extract Type (e.g. Enrolment Form Extract, Testamur Extract).
Data in the Extract Tables is stored in a generic format, in fields with generic names. The main body of information for each record is stored in a single, generic, pipe delimited string. The views break down this information, presenting each element of a record in a separate field. In the views, the 'key' fields are given their natural names, e.g. PERSON_ID, CREATE_DT, AWARD_CD etc. (rather than the generic names used in the Extract Tables). The pipe delimited string from an Extract Table is split into separate fields, named FIELD1, FIELD2 etc. in the corresponding view. This enables extracts which produce more than one record type to be accommodated.
Custom Programs
Individual institutions can custom build programs to use the data presented by extract views. If required, additional data can be extracted from other Callista tables by the custom program. Each program relates to a specific Extract Type. The institution can determine what type of output their custom program produces. For example, output from an Enrolment Form program could be in the form of a printed report or printed correspondence items, a file for bureau printing or display for on-line forms.
Examples of Jobs Producing Extract Files
This list is not meant to be exhaustive, purely examples of extract files. See also Inquiry, Scholarships, Statistics, etc for other extract files:
Last Modified on 9 September, 2009 6:10 PM
History Information
| Release Version | Project | Change to Document |
| 10.1.0.0.0.0 | C21627 | Update Examples |